Professional Services
Custom Software
Managed Hosting
System Administration
See my CV here.
Send inquiries here.
Open Source:
tCMS
trog-provisioner
Playwright for Perl
Selenium::Client
Audit::Log
rprove
Net::Openssh::More
cPanel & WHM Plugins:
Better Postgres for cPanel
cPanel iContact Plugins
I have to have a solution for every major OS, as this is a
necessity for testing software properly.
On Linux I can pretty much have everything I need on one to N+1
virtual desktops, where N is the number of browsers I need to
support, plus one window for doing documentation lookups (usually
on a second monitor). I do most of my development on linux
for precisely these reasons.
This mostly works the same on OSX, however they break immersion
badly for people like me by having:
They seemed to have optimized for the user which Alt+Tabs between
700 open windows in one workspace, which is a good way to break
flow with too much clutter.
On windows VSCode has a good shortcut to summon the console, and
a vim plugin that works great. Windows virtual desktops also
work correctly, and I can configure shortcuts on linux to match
both it and the console summon. I would prefer it be the
other way around, but commercial OS interface programmers tend to
either be on a power trip or too afraid of edge cases to allow
user choice. If I could have a tmux-like shortcut to page
between vscode workspaces like I do panes I'd be a happier camper,
as I wouldn't need as many virtual desktops. This is
apparently their most popular
feature request right now, go figure.
Beyond the little hacks you do to increase flow, mitigating the
impact of interruptions is important. This is a bit more
difficult as much of this is social hacking, and understanding
human nature. The spread of computing into the general
population has also complicated this as the communication style of
the old order of programmers and engineers is radically different
from the communication norms of greater society. I, along
with much of the rest of my peers, are still having a difficult
time adjusting to this.
The preferred means of communication
for engineers is information-primary rather than
emotion-primary. The goal of communication is to convey
information more than feeling (if that is communicated at
all). The majority of society does not communicate in this
fashion. Instead they communicate Feelings above all else
and Information is of secondary (if any) importance. For
these people, their resorting to communication of information
is a sign of extreme frustration that you have not yet
discerned their emotional message and provided the validation they
are seeking. If they haven't already lashed
out, they are likely on the way to doing so.
It is unfortunate to deal with people operating via a juvenile
and emotional communication style, but this is the norm in society
and over the last 20 years has entirely displaced the existing
engineering culture at every firm I've worked at. Code
reviews can no longer be blunt, as it is
unlikely you are dealing with someone who is not seeking
validation as part of their communication packets. The punky
elements of culture which used to build friendship now build
enmity (as you are dealing with the very "squares" nerd culture
embraced being hated by). Nevertheless, you still have to
walk in both worlds as there are still islands of other hackers
just like you. Taking on and off these masks is risky,
however, as people are quite hung up on the notion that people
must be 100% congruent with how they are perceived outwardly.
Everyone out there building an online reputation learns quickly
that courting controversy will get you far more engagement than if
you had made a program which cured eczema and allowed sustained
nuclear fusion. Emotional highs punctuated by warm fuzzies is
generally the sort of rollercoaster ride people are looking
for. Lacking better sources they will attempt to draw you
into their emotional world. Their world is a skinner box,
and if you enter it unawares they will train you.
They cannot help but be this way, so you must turn off the part
of your brain that looks for informational meaning in mouth
noises. Their utterances have little more significance than
the cries of a baby or yapping of a dog. The only thing that
matters is whether the behavior is something you wish to encourage
or discourage.
Operant conditioning is how you must regard your
interactions. When you validate them (usually with
attention), you encourage that behavior. Non-acknowledgement
of irritating behavior is often the most effective
discouragement. The natural urge to engage with any point of
fact must be resisted, and instead reserve your communications to
that which advances your purposes. When a minimum of
validation is demanded, dismissal via fogging, playing
dumb or broken-record technique should be engaged in, rather than
the hard no which is deserved. A satisfying response to a
demand can never be offered unless you wish to be dominated by
those around you. Many see this as Machiavellian
manipulation, but there is no choice. You play this game, or
get played.
Nevertheless, this all has a huge effect on the corporate
environment. Most firms devote far more energy to playing
house than pleasing customers and making money, and tech is no
exception. Fellow employees are far more likely to seek
validation on this schedule with each other than
customers. Most satisfy themselves with a stable IV drip of
validation from their local group rather than experiencing the
much more rewarding experience of solving customer problems.
This should come as no shock, given social media is purpose built
to inculcate this mental model, as it was found to maximize
engagement. This is also good at building solidarity at a
firm but unfortunately comes at the expense of crowding-out
emotional investment in the customer who cannot and should not
have so tight an OODA loop with their vendors.
You break out of your loop when you stop getting meaningful
observations. Many organizations have successfully adopted
this (see OPCDA). The
whole point here is that you accumulate less bad designs
lurking in your code, as you can refine constraints quickly enough
to not over-invest in any particular solution.
For those of you not familiar with me, I have a decade of
experience automating QA processes and testing in general.
This means that the vast majority of my selling has been of two
kinds:
That said, I also wore "all the hats" in my startup days at
hailstrike, and had to talk a customer down from bringing their
shotgun to our office.
I handled that one reasonably well, as the week beforehand I'd
read Carl Sewell's Customers
for Life and Harry Browne's Secret
of selling anything.
The problem was that one of the cronies of our conman CEO was a
sales cretin there and promised the customer a feature that didn't
exist and didn't give us a heads up.
It took me a bit to calm him down and assure him he was talking to
a person that could actually help him, but after that I found out
what motivated him and devised a much simpler way to get him what
he wanted.
A quick code change, a deploy and call back later to walk him
through a few things to do on his end to wrangle data in Excel and
we had a happy camper.
He had wanted a way to bulk import a number of addresses into our
systems and get a list of hailstorms which likely impacted the
address in question, and a link into our app which would pull the
storm map view immediately (that they could then do a 1-click
report generate for homeowners).
We had a straightforward way of doing this for one address at a
time, but I had recently completed optimizations that made it
feasible to do many as part of our project to generate reports up
to two years back for any address.
Our application was API driven and already had a means to process
batched requests, so it was a simple matter of building an excel
macro talking to our servers which he could plug his auth
credentials into.
I built this that afternoon and sent it his way. This
started a good email chain where we made it an official feature of
the application.
It took a bit longer to build this natively into our application,
but before the week was up I'd plumbed the same API calls up to
our UI and this feature was widely available to our customers.
I was also able to give a stern talking to our sales staff (and
gave them copies of C4L and SSS) which kept this from happening
going forward, but the company ultimately failed thanks to
aforementioned conman CEO looting the place.
After that experience I went back to being a salaryman over at
cPanel. There I focused mostly on selling productivity tools
internally until I transitioned into a development role.
I'd previously worked on a system we called "QAPortal" which was
essentially a testing focused virtual machine orchestration
service based on KVM. Most of the orchestration
services we take for granted today were in their infancy at
that time and just not stable or reliable enough to do the
job. Commercial options like CloudFormation or VSphere were
also quite young and expensive, so we got things done using perl,
libvirt and a webapp for a reasonable cost. It also had some
rudimentary test management features bolted on.
That said, it had serious shortcomings, and the system
essentially was unchanged for the 2 year hiatus I had over at
hailstrike as all the developers moved on to something else after
the sponsoring manager got axed due to his propensity to have
shouting matches with his peers.
I was quickly tasked with coming up with a replacement. The
department evaluated test management systems and eventually
settled on TestRail, which I promptly wrote the perl API client
for and put it on CPAN.
The hardware and virtual machine orchestration was replaced with
an openstack cluster, which I wrote an (internal) API library for.
I then extended the test runner `prove` to talk to and multiplex
it's argument list over the various machines we needed to
orchestrate and report results to our test management system.
All said, I replaced the old system within about 6 months.
If it were done today, it would have taken even less time thanks
to the advances in container orchestration which have happened in
the intervening time. The wide embrace of SOAs
has made life a lot better.
Now the team had the means to execute tests massively in parallel
across our needed configurations, but not every team member was
technical enough to manage this all straightforwardly from the
command line. They had become used to the old interface, so
in a couple of weekends I built some PHP scripts to wrap our apps
as an API service and threw up a jQuery frontend to monitor test
execution, manage VMs and handle a few other things the old system
also accomplished.
Feedback was a lot easier than with external customers, as my
fellow QAs were not shy about logging bugs and feature requests.
I suspect this is a lot of the reason why companies carefully cultivate alpha and beta testers from their early adopter group of rabid fans. Getting people in the "testing mode" is a careful art which I had to learn administering exploratory test sessions back at TI, and not to be discarded carelessly. That is essentially the core of the issue when it comes to getting valid reports back from customers. You have to do Carl Sewell's trick of asking "what could have worked better, what was annoying...", as those are the sort of user feedback that you want rather than flat-out bugs. Anything which breaks the customers' immersion in the product must be stamped out -- you always have to remember you are here to help the user, not irritate them.
Rewarding these users with status, swag and early access was the
most reliable way to weed out time-wasters; you only want people
willing to emotionally invest, and that means rewards have to
encourage deeper integration with the product and the
business. It also doesn't hurt that it's a lot cheaper and
easier to justify as expenses than bribes.
Measuring adoption of software and productivity ideas in general
can be tricky unless you have a way to either knock on the door or
phone home. Regardless of the approach taken, you also have to
track it going forwards, but thankfully software makes that part
easy nowadays.
Sometimes you use A/B tests and other standard conversion metrics,
as I used extensively back at HailStrike. I may have tested
as much copy as I did software! Truly the job is just
writing and selling when you get down to it.
In the case of inter-organization projects most of the time it's
literally knocking on the door and talking to someone. At
some level people are going to "buy" what you are doing, even if
it's just giving advice. This is nature's way of telling you
"do more of this, and less of the rest".
I can say with confidence that the best tool for the job when it
comes to storing this data is a search engine, as you eventually
want to look for patterns in "what worked and didn't".
Search engines and Key-Value stores give you more flexibility in
what IR
algorithm best matches the needs of the moment. I use
this trick with test data as well; all test management systems use
databases which tend to make building reports cumbersome.
Rather than flippantly dismiss the original question, I would
like to revisit the problem. While it is obvious that I will
probably gain more over the long term by sacrificing my desire to
do something fun instead of writing this article, one must also
take into consideration the law of diminishing
marginal utility and the Paradox of Value. Thinking
long term means nothing when one is insolvent or dead without
heirs tomorrow. There will always be an infinite number of
possible ends for which I sacrifice my finite means. As an
optimization problem, it is NP hard. The best we can do is
to use the Kelly
Criterion to distribute our time and other assets wisely
among the opportunities we best understand the risks about.
Building an online reputation is quite expensive and time
consuming, but is beginning to pay off. It doesn't hurt that
I'm pursuing multiple aims simultaneously (building a MicroISV
product, chasing contracts) with everything I write these
days. That said it cannot be denied that hanging out your
shingle is tantamount to a financial suicide mission without
multiple years of runway. Had I not spent my entire adult
life toiling, living below my means and not taking debts, none of
this would be possible. In many ways it's a lot like going
back to college, but the hard knocks I'm getting these days have
made me learn a whole lot more than a barrel full of professors.
For those who insist on the technical answer to this question, I
would direct you to observe the design of Selenium::Client
versus that of Selenium::Remote::Driver.
This is pretty much my signature case
for why picking a good design from the beginning and putting in
the initial effort to think is worth it. My go-to approach
with most big balls
of mud is to stop the bleeding with modular design.
Building standalone plugins that can ship by themselves was a very
effective approach at cPanel, and works very well when dealing
with Bad
and Right systems. What is a lot harder to deal with
is "Good and Wrong" systems, usually the result of creationist
production. When dealing with a program that puts users and
developers into Procrustes' bed
rather than conforming to their needs you usually have to start
back from 0. Ironically most such projects are the result of
the misguided decision to "rewrite it, but correctly this time".
Given cPanel at the time was a huge monorepo sort of personifying
"bad design, good execution", many "lets rewrite it, but right
this time" projects happened and failed, mostly due to having
forgotten the reasons it was written the way it had been in the
first place. New versions of user interfaces failed to
delight users thanks to removing features people didn't know were
used extensively or making things more difficult for users in the
name of "cleaner" and "industry standard" design. A lot of
pain can be brought to a firm when applying development standards
begins to override pleasing the customer. The necessity of
doing just that eventually resulted in breaking the monolith to
some extent, as building parallel distribution mechanisms was the
only means to escape "standardization" efforts which hindered
satisfying customer needs in a timely manner.
This is because attempting to standardize across a monorepo
inevitably means you can't find the "always right" one-size
fits-all solution and instead are fitting people into the iron
bed. The solution of course is better organizational
design rather than program design, namely to shatter the
monolith. This is also valuable at a certain firm scale
(dunbar's number again), as nobody can fit it all into their head
without resorting to public interfaces, SOA and so forth.
Reorientation to this approach is the textbook
example of short-term pain that brings long-term benefit,
and I've leveraged it multiple times to great effect in my career.
I have been fired multiple times in my life. Each time it has been because I violated a fundamental rule of power. Where I had stayed employed when others were cut it was also due to "observation of the laws" of power. This is not to say I understood this at the time, but to observe that "this time is not different".
The first "real job" I got out of college was testing calculators for Texas Instruments. I subcontracted there for about 4 years, and was one of the few who survived a ruthless layoff associated with the 07/08 panic. This was a very close run thing. There was one day in which I was fired and re-hired in the same day.
It is clear in retrospect that the reason I stuck around was due to being better at finding issues than all my peers. I had by that time found a number of critical issues with the multi-line scientifics by mapping out the memory pages and watching for stomped flags. Nobody else testing the products at the time came close to understanding the hardware at this level, making me indispensable.
Which is to say I focused like a good protestant work ethic boy on
laws #9 and #11.
Demonstrate, don't explicate. Keep others dependent on you to
achieve freedom.
I keep going back to this over my career, as it worked.
I also learned law #13 "Only appeal to self-interest" when it
came to seeking promotion and favor from management. I found
quickly that "job descriptions" were universally meaningless and
the only important thing was delivering on stuff your manager was
emotionally invested in.
This was about two years before I got fired. I went on to do more things for the firm which nobody else understood, such as solving a data encoding issue with archival documents and porting the TI-8X emulator to linux. I had made a good number of friends and was well liked at the firm.
Nevertheless, this made me a bit too comfortable. I was also still a pretty naive young man at the time, and actually believed upper management would appreciate serious criticism. This is of course not the case, and they see it as an affront and out of place. To do this is to violate rules of power #1 and #19, "Don't outshine the master" and "Don't offend the wrong people". Like my victories this has also bitten me more than once.
Interestingly enough a couple of months after my ouster, I got an offer to work on the programming of the color TI-84 from one of the programmers there I had a good relationship with. Apparently the criticisms which I had of management were quite timely and the issues I had brought up promptly blown up in their face like backdraft. As such, there was no resistance to my return as all oxen gored were now out of the picture.
I had taken a job with cPanel by then though, a firm which I would spend 8 years at. I also rapidly rose to a position of indispensability in the QA organization there, but took a brief hiatus to work with my cousin at his startup HailStrike. In retrospect this should have been an obvious violation of Power law #10 "avoid the unhappy and unlucky". The company was a reject bin in many ways.
Nevertheless due to my upbringing which had turned me into the stereotypical "nice guy" who immolates himself to keep others warm, I did a lot of good work there. I built a new product from the ground up and re-wrote the existing one to not have horrible projection bugs and awful performance. That said, nothing could save that firm, as my cousin and his partner hired a con-man to run the firm thanks to their lack of self-confidence. After about a year and a successful funding round, the co-founders went on a month long vacation and returned to find the place looted.
In that time and in the aftermath I basically kept tech end of the shop going single-handedly for minimum wage. After about 6 months of this I cut bait and returned to cPanel, being close to "zeroed out" financially. All I got for the trouble was some worthless stock in a firm which languishes to this day.
Meanwhile cPanel's QA department hadn't changed much from where I had left it. They were eager to make some forward progress and remembered my impact. So my departure at least had the positive effect of resulting in a big raise. Law #16 "Use absence to increase respect and honor" in action.
For the next 5 or so years I became the most senior man in the department. I made a number of tools without which the department couldn't do their jobs. I also was #1 across the board in test execution and bug filing metrics.
So far, so good.
I also cultivated better options to effect a promotion and
significant raise in my last two years, but this would prove my
undoing.
Much ink has been spilled about how it's always better to take the
other offer (much of which I had read!) but I was emotionally
invested in the firm after 6 years and accepted the counteroffer.
I was now writing product code rather than automation for our QA workflow. Similar to in my prior role, I quickly rose to the top 5 bug fixers and committers at the firm. This, however is not the same as indispensability.
It turns out that you need to work on products that matter if you want to stick around. At TI, I worked on cash cows, and these things will forever need their indispensable people. However at cPanel they had a monoproduct which was itself an aglommeration of various sub-products some of which were important and not. The teams I was put on were rarely working on anything the customer was particularly interested in.
To be fair, this is the case across much of the organization. For years only the CEO's team was the one working on anything relevant to customers. The rest of the firm was run autonomously by the middle management and fell victim to the principal-agent problems that entails.
As a middle manager, to aggrandize yourself you generally want to weed out the indispensable and maximize your headcounts. This is generally accomplished by two means:
I was eventually assigned a new team and manager which I should in retrospect have realized was a trap. I had built quite the reputation for independence while I was there (which is normal with the indispensable) and clashed multiple times with this manager. Enough things piled up over time which were not explicitly breaking the rules but did not signal submission that he formed a negative opinion of me. I'd been making a number of other changes in my life at the time which were bringing refreshing youthful joy, so I suppose it is not surprising I returned to the indiscretions from my youth which tripped me up at TI.
All it took from there was a minor dispute which could easily have
been resolved peacefully being escalated in bad faith. Some
of this was simply because I fought the situation at all.
Bosses like to feel like the "cop" in the relationship in these
situations, and we all know how cops feel about anyone who doesn't
instantly surrender, grovel and degrade themselves for daring to
attract their ire. This is why rule of power #22 is a thing.
Surrender is the best option in such situations where you are
already "caught up", as bosses think any benevolence they show
from that point is a thumb-screw they can use on demand. Obviously
you would prefer these thumbscrews not be used, so the tactic is
to buy time and enough freedom of action to get out of there.
Rule #42 also comes into play, "Strike the Shepard and the sheep
scatter". Even if you are in the right, management cannot
tolerate defiance spreading. It's simply inviting further
attack. While this is effective at keeping management
powerful, it also has the effect of entrenching whatever errors
they are engaged in.
At the end of the day the question that must be asked is "would
you rather be happy, or right?" Being emotionally invested
in the firm you work for and your role in it means it must
"do right" in order for you to be happy. This is a recipe
for disaster, as everyone's emotional needs from the firm differ
and become guaranteed to clash past Dunbar's
number. This is why Power law #20 is a thing: "commit
to no one".
This desire to have a useful culture at a company and a good "mission" is power law #27, "Use people's need to believe to create a cult-like following". While you can't hate the player for "playing the game", it is straightforward to realize that there are a great deal better things out there to direct your belief and worship towards than a corporation. All the senior developers I've known who were checked out totally about the firm had the right idea all along. The company can want a certain culture all it wants and even go to great lengths to inculcate it, but it simply can't work past a certain scale. You have to insulate yourself from this and resist getting sheep-dipped into their hyperreality if you want to remain happy. Focus instead on doing the things that give you power over your situation, which is real freedom.
The shock of being removed from a place I'd been 8 years with a
number of good friends took a while to absorb, but it's pretty
clear where I steered wrongly.
I should have learned the lesson of the Count
of Carmagnola.
You can't be a star when what they need is a cog.
When preparing any tool which you see all the pieces readily available, but that nobody has executed upon, you begin to ask yourself why that is. This is essentially what I've been going through building the pairwise tool.
Every time I look around and don't see a solution for an
old problem on CPAN, my spider-senses start to fire. I saw
no N-dimensional combination methods (only n Choose k) or bin
covering algorithms, and when you see a lack of N-dimensional
solutions that usually means there is a lack of closed form
general solutions to that problem. While this is not true
for my problem space, it rubs right up against the edge of NP hard
problems. So it's not exactly shocking I didn't see anything
fit to purpose.
The idea behind pairwise
test execution is actually quite simple, but the constraints
of the software systems surrounding it risk making it more complex
than is manageable. This is because unless we confine ourselves to
a very specific set of constraints, we run into not one, but two
NP hard problems. We could then be forced into the unfortunate
situation where we have to use Polynomial time approximations.
I've run into this a few times in my career. Each time the team
grows disheartened as what the customer wants seems on the surface
to be impossible. I always remember that there is always a way to
win by cheating (more tight constraints). Even the tyranny of the
rocket equation was overcome through these means (let's put a
little rocket on a big one!)
The first problem is that N-Wise test choosing is simply a combination.
This results in far, far more platforms to test than is practical
once you get beyond 3 independent variables relevant to your
system under test. For example:
A combination with 3 sets containing 3, 5 and 8 will result in 3
* 5 * 8 = 120 systems under test! Adding in a fourth or fifth will
quickly bring you into the territory of thousands of systems to
test. While this is straightforward to accomplish these
days, it is quite expensive.
What we actually want is an expression of the pigeonhole
principle. We wish to build sets where every
element of each component set is seen at least once, as
this will cover everything with the minimum number of needed
systems under test. This preserves the practical purpose of
pairwise testing quite nicely.
In summary, we have a clique problem and a bin covering problem. This means that we have to build a number of bins from X number of sets each containing some amount of members. We then have to fill said bins with a bunch of tests in a way which will result in them being executed as fast as is possible.
Each bin we build will represent some system under test, and each set from which we build these bins a particular important attribute. For example, consider these sets:
A random selection will result in an optimal multi-dimensional "pairwise" set of systems under test:
The idea is to pick one of each of the set with the most members
and then pick from the remaining ones at the index of the current
pick from the big set modulo the smaller set's size. This is the
"weak" form of the Pigeonhole Principle in action, which is why it
is solved easily with the Chinese
remainder theorem.
You may have noticed that perhaps we are going too far with our constraints here. This brings in danger, as the "strong" general form of the pigeonhole principle means we are treading into the waters of Ramsey's (clique) problem. For example, if we drop either of these two assumptions we can derive from our sets:
We immediately descend into the realm of the NP hard problem.
This is because we are no longer a principal ideal domain and can
no longer cheat using the Chinese remainder theorem. In this
reality, we are solving the Anti-Clique
problem specifically, which is particularly nasty. Thankfully, we
can consider those two constraints to be quite realistic.
We will have to account for the fact that the variables are
actually not independent. You may have noticed that some of these
"optimal" configurations are not actually realistic. Many
Operating systems do not support various processor architectures
and software packages. Three of the configurations above are
currently invalid for at least one reason. Consider a
configuration object like so:
Can we throw away these configurations without simply
"re-rolling" the dice? Unfortunately, no. Not without
using the god
algorithm of computing every possible combination ahead of
time, and therefore already knowing the answer. As such our
final implementation looks like so:
This brings us to another unmentioned constraint: what happens if
a member of a set is incompatible with all members of another
set? It turns out accepting this is actually a significant
optimization, as we will end up never having to re-roll
an entire sequence. See the while loop above.
Another complication is the fact that we will have to randomize
the set order to achieve the goal of eventual coverage of every
possible combination. Given the intention of the tool is to run
decentralized and without a central oracle other than git,
we'll have to also have use a seed based upon it's current
state. The algorithm above does not implement this,
but it should be straightforward to add.
We at least have a solution to the problem of building the bins. So, we can move on to filling them. Here we will encounter trade-offs which are quite severe. If we wish to accurately reflect reality with our assumptions, we immediately stray into "no closed form solution" territory. This is the Fair Item Allocation problem, but with a significant twist. To take advantage of our available resources better, we should always execute at least one test. This will result in fewer iterations to run through every possible combination of systems to test, but also means we've cheated by adding a "double spend" on the low-end. Hooray cheating!
The fastest approximation is essentially to dole out a number of
tests equal to the floor of dividing the tests equally among the
bins plus floor( (tests % bins) / tests ) in
the case you have less tests than bins. This has an error which is
not significant until you reach millions of tests. We then get
eaten alive by rounding error due to flooring.
It is worth noting there is yet another minor optimization in our
production process here at the end, namely that if we have more
systems available for tests than tests to execute, we can achieve
total coverage in less iterations by repeating tests from earlier
groups.
Obviously the only realistic assumption here is #2. If tests can be executed faster by breaking them into smaller tests, the test authors should do so, not an argument builder.
Assumptions #1 and #3, if we take them seriously would not only doom us to solving an NP hard problem, but have a host of other practical issues. Knowing how long each test takes on each computer is quite a large sampling problem, though solvable eventually even using only git tags to store this data. Even then, #4 makes this an exercise in futility. We really have no choice but to accept this source of inefficiency in our production process.
Invalidating #5 does not bring us too much trouble. Since we expect to have a number of test hosts which will satisfy any given configuration from the optimal group and will know how many there are ahead of time, we can simply split the bin over the available hosts and re-run our bin packer over those hosts.
This will inevitably result in a situation where you have an
overabundance of available systems under test for some
configurations and a shortage of others. Given enough tests, this
can result in workflow disruptions. This is a hard problem to
solve without "throwing money at the problem", or being more
judicious with what configurations you support in the first place.
That is the sort of problem an organization wants to have though.
It is preferable to the problem of wasting money testing
everything on every configuration.
Since the name of the tool is pairwise, I may as well also
implement and discuss multi-set combinations. Building these
bins is actually quite straightforward, which is somewhat shocking
given every algorithm featured for doing pairwise testing at
pairwise.org was not in fact the optimal one from my 30 year old
combinatorics textbook. Pretty much all of them used
tail-call recursion in languages which do not optimize this, or
they took (good) shortcuts which prevented them from functioning
in N dimensions.
Essentially you build an iterator which, starting with the first
set, pushes a partial combination with every element of its set
matched with one of the second onto your stack.
You then repeat the process, considering the first set to be the
partial, and crank right through all the remaining sets.
Dealing with incompatibilities is essentially the same procedure
as above. The completed algorithm looks like so:
You may have noticed this is a greedy algorithm. If we
decided to use this as a way to generate a cache for a "god
algorithm" version of the anti-clique generator above, we could
very easily run into memory exhaustion with large enough
configuration sets, defeating the purpose. You could flush the
partials that are actually complete, but even then you'd only be
down to 1/n theoretical memory usage where n is the size of your
2nd largest configuration set (supposing you sort such that it's
encountered last). This may prove "good enough" in practice,
especially since users tend to tolerate delays in the "node added
to network" phase better than the "trying to run tests"
phase. It would also speed up the matching of available
systems under test to the desired configuration supersets, as we
could also "already know the answer".
Profiling this showed that I either had to fix my algorithm or
resort to this. My "worst case" example of 100 million tests
using the cliques() method took 3s, while generating everything
took 4. Profiling shows the inefficient parts are almost
100% my bin-covering.
Almost all of this time is spent splice()ing huge arrays of
tests. In fact, the vast majority of the time in my test
(20s total!) is simply building the sequence (1..100_000_000),
which we are using as a substitute for a similar length argument
array of tests.
We are in luck, as once again we have an optimization suggested
by the constraints of our execution environment. Given any
host only needs to know what it needs to execute we can
save only the relevant indices, and do lazy
evaluation. This means our sequence expansion (which
takes the most time) has an upper bound of how long it takes to
generate up to our offset. The change is
straightforward:
The question is, can we cheat even more by starting at our offset
too? Given we are expecting a glob or regex describing a
number of files which we don't know ahead of time what will be
produced, this seems unlikely. We could probably speed it up
globbing with GLOB_NOSORT. Practically
every other sieve trick we can try (see DeMorgan's
Laws) is already part of the C library implementing glob
itself. I suspect that we will have to understand the parity
problem a great deal better for optimal
seeking via search criteria.
Nevertheless, this gets our execution time for the cliques()
algorithm down to 10ms, and 3s as the upper bound to generate our
sequence isn't bad compared to how long it will take to execute
our subset of 100 million tests. We'd probably slow the
program down using a cached solution at this point, not to mention
having to deal with the problems inherent with such.
Generating all combinations as we'd have to do to build the cache
itself takes another 3s, and there's no reason to punish most
users just to handle truly extreme data sets.
It is possible we could optimize our check that a combination is
valid, and get a more reasonable execution time for combine() as
well. Here's our routine as a refresher:
Making the inner grep a List::Util::first instead seems obvious,
but the added overhead made it not worth it for the small data
set. Removing our guard on the other hand halved execution time,
so I have removed it in production. Who knew ref( ) was so
slow? Next, I "disengaged safety protocols" by turning off
warnings and killing the defined check. This made no
appreciable difference, so I still haven't yet run into a
situation where I've needed to turn off warnings in a tight
loop. Removing the unnecessary allocation of @compat and
returning directly shaved another 200ms. All told, I got
down to 800ms, which is in "detectable but barely" delay
territory, which is good enough in my book.
The thing I take away from all this is that the most useful thing
a mathematics education teaches is the ability to identify
specific problems as instances of generalized problems (to which a
great deal of thinking has already been devoted). While this
is not a new lesson, I continuously astonish myself how
unreasonably effective it is. That, and exposure to the wide
variety of pursuits in mathematics gives a leg up as to where to
start looking.
I also think the model I took developing this has real
strength. Developing a program while simultaneously doing
what amounts to a term paper on how it's to operate very clearly
draws out the constraints and acceptance criteria from a program
in an apriori way. It also makes documentation a fait
accompli. Making sure to test and profile while doing this
as well completed the (as best as is possible without users) methodologically
dual design, giving me the utmost confidence that this
program will be fit for purpose. Given most "technical debt"
is caused by not fully understanding the problem when going into
writing your program (which is so common it might shock the
uninitiated) and making sub-optimal trade-offs when designing it,
I think this approach mitigates most risks in that regard.
That said, it's a lot harder to think things through and then
test your hypotheses than just charging in like a bull in a china
shop or groping in the dark. This is the most common pattern
I see in practice doing software development professionally.
To be fair, it's not like people are actually willing to pay
for what it takes to achieve real quality, and "good enough" often
is. Bounded
rationality is the rule of the day, and our lot in life is
mostly that of a satisficer.
Optimal can be the enemy of good, and the tradeoffs we've made
here certainly prove this out.
When I was doing QA for a living people are surprised when I tell
them the most important book for testers to read is Administrative
Behavior. This is because you have to understand the
constraints of your environment do do your job well, which is to
provide actionable information to decision-makers. I'm
beginning to realize this actually suffuses the entire development
process from top to bottom.
Basically nothing about the response on social media to my prior post has shocked me.
The very first response was "this is a strawman". Duh. It should go without saying that everyone's perception of others can't be 100% accurate. I definitely get why some people put "Don't eat paint" warnings on their content, because apparently that's the default level of discourse online.
Much of the rest of the criticism is to confuse "don't be so nice" with "be a jerk". There are plenty of ways to politely insist on getting your needs met in life. Much of the frustrations Sawyer is experiencing with his interactions are to some degree self-inflicted. This is because he responds to far too much, unwittingly training irritating people to irritate him more.
This is the most common failure mode of "look how hard I tried". The harder you "try" to respond to everything, the worse it gets. Trust me, I learned this the hard way. If you instead ignore the irritating, they eventually "get the message" and slink off. It's a simple question: Would you rather be happy, or right? I need to be happy. I don't need other people to know I'm right.
I'm also not shocked that wading into drama / "red-meat" territory got me more engagement on a post than anything else I've got up here to date. This is just how things work online -- controversy of some kind is necessary. Yet another reason to stop being nice; goring someone's ox is just the kind of sacrifice needed to satiate the search engine gods, apparently.
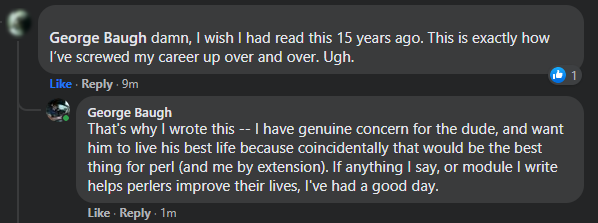
This is not to say I don't find it distasteful, indeed there is a reason I do not just chase this stuff with reckless abandon. What I want is to have a positive impact on the community at large, and I think I may just have done it (see the image with this post).
Even though I gored a few oxen-feels posting this, it's clearly made a positive impact on at least one person's life. That alone makes it worth it. I still take the scout's vow to do a good turn daily seriously. Keep stacking those bricks, friends.
SawyerX has resigned from the Perl 5 steering council. This is unfortunate for a variety of reasons, the worst of which is that it is essentially an unnecessary self-sabotage which won't achieve Sawyer anything productive.
I met Sawyer in a cafe in Riga during the last in-person EU Perl 5/6 con. Thankfully much of the discussion was of a technical nature, but of course the drama of the moment was brought up. Andrew Shitov, a Russian was culturally insensitive to westerners, go figure. He apologized and it blew over, but some people insisted on grinding an axe because they valued being outraged more than getting on with business.
It was pretty clear that Sawyer was siding with the outraged, but still wanted the show to go on. I had a feeling this (perceived) fence-sitting would win him no points, and observed this play out.
This discussion naturally segued into his experience with P5P, where much the same complaints as lead to his resignation were aired. At the time he was a pumpking, and I stated my opinion that he should just lead unrepentantly. I recall saying something to the effect of "What are you afraid of? That people would stop using perl? This is already happening." At the time it appears he was just frustrated enough to actually lead.
This lead to some of the most forward progress perl5 has had in a long time. For better or worse, the proto-PSC decided to move forward. At the time I felt cautiously optimistic because while his frustration was a powerful motivator, I felt that the underlying mental model causing his frustration would eventually torpedo his effort.
This has come to pass. The game he's playing out here unconsciously is called "look how hard I'm trying". It's part of the Nice Guy social toolkit. Essentially the worldview is a colossal covert contract: "If I try hard and don't offend anyone, everyone will love me!"
It's unsurprising that he's like this, as I've seen this almost everywhere in the software industry. I was like this once myself. Corporate is practically packed from bottom to top with "nice guys". This comes into conflict with the big wide world of perl, as many of the skilled perlers interested in the core language are entrepreneurs.
In our world, being nice gets you nowhere. It doesn't help you in corporate either, but corporate goes to great effort to forestall the cognitive dissonance which breaks people out of this mental model. The reason for this is straightforward. Studies have repeatedly shown those with agreeable personalities are paid less.
Anyways, this exposes "nice" people to rationally disagreeable and self-interested people. Fireworks ensue when their covert contract is not only broken, but laughed at. Which brings us to today, where Sawyer's frustration has pushed him into making a big mistake which he thinks (at some level, or he would not have done it) will get him what he wants.
It won't. Nobody cares how hard you worked to make it right. Those around you will "just say things" forever, and play what have you done for me lately on repeat until the end of time. Such is our lot as humans, and the first step in healing is to accept it.
Future people considering hiring Sawyer will not have a positive view of these actions. Rather than seeing the upright and sincere person exhausted by shenanigans that Sawyer sees in himself, they will see a person who cracked under pressure and that therefore can't be trusted for the big jobs.
I hate seeing fellow developers make some of the same mistakes I did earlier in life. Especially if the reason he cracked now has to do with other things going on in his personal life which none of us are or should be privy to. Many men come to the point where it's "Kill the nice guy, before he kills you". Let us hope the situation is not developing into anything that severe, so that he can right his ship and return to doing good work.
I'm borrowing the title of a famous post by patio11,
because I clearly hate having google juice because it's good and touches on similar points to my former colleague Mark Gardner recently made.
(See what I did there, cross site linking! Maybe I don't hate having google juice after all...)
Anyways, he mentioned that despite having a sprint fail, he still learned a lot of good stuff. This happens a lot as a software developer and you need to be aware of this to ensure you maximize your opportunities to take something positive away from everything you work on.
On that note, I had a similar thing happen to me this week with playwright-perl. It turns out I didn't have to write a custom server with express to expose the Playwright API to Perl. The Playwright team have a command line program which talks on stdin/stdout to do these RPC calls for their python and go clients.
The reason I didn't know about it was that it is not documented! The only reason I found out was due to hopping into the Playwright slack and getting some good feedback from one of the Playwright devs.
This might seem like I did a bunch of work for no reason, and now have to do expensive re-tooling. I actually don't have to do anything if I don't want to. My approach seems to work quite well as-is. That said, even when I do replace it (as this will be good from a maintenance POV), the existing code can be re-used to make one of the things I really want. Namely, a selenium server built with playwright.
This would give me all the powerful new features, reliability and simpler setup that traditional Selenium servers don't have. Furthermore, (if it catches on) it means the browser vendors can stop worrying about releasing buggy selenium driver binaries and focus on making sure their devToolsProtocols are top-shelf. (Spoiler alert: This is one of the secret reasons I wrote Selenium::Client.)
This also shouldn't be too much of a hurdle, given I have machine-readable specs for both APIs, which means it's just a matter of building the needed surjections. Famous last words eh? Should make for an interesting Q3 project in any case.
Last week Sebastian Riedel did some mojo testing using Playwright, I encourage you to see his work here. It would have been neat if he'd used my playwright module on CPAN (as it was built to solve this specific problem). He did so in a way which is inside-out from my approach.
That's just fine! TIMTOWTDI is the rule in Perl, after all. For me, this underlines one of the big difficulties for even a small OSS developer; If you build it, nobody will come for years if you don't aggressively evangelize it.
On that front, I've made some progress; playwright-perl got a ++ from at least one other PAUSE author and I got my first ever gratuity for writing open source software thanks to said module. This is a pretty stark contrast from the 100% thankless task of Selenium::Remote::Driver, which is a lot more work to maintain.
This is a good point to segue into talking about Sebastian's article. Therein he mentions that some of the tricks Playwright are using might end up being a maintenance landmine down the road. Having both worked at a place which has maintained patches to upstream software for years at a time and maintained a selenium API client for years I can say with confidence this is less of a problem than selenium has.
The primary trouble with selenium over the years has to do with the fact that it is simply not a priority for any of the browser vendors. The vast majority of issues filed on Selenium::Remote::Driver over the years have been like this one: In essence, the browser vendor issues a broken driver for a release and we either can ignore it as transient or have to add a polyfill if it persists across releases. Selenium::Remote::Driver is more polyfill than client at this point (partially due to the new WC3 selenium standard not implementing much of the older JSONWire spec).
Historically, Chrome has been the biggest repeat offender in releasing broken drivers. However post-layoffs, it appears Mozilla is getting in on this game as well. Add people frequently using drivers of versions which are incompatible with their browser and encountering undefined behavior, and you begin to understand why microsoft decided to micromanage the browsers the way they did in Playwright. In practice, you need this level of control to have your testing framework be less buggy than the system you want to test with it.
In the end, the reason selenium sticks to open protocols is because they don't have the resources to devote to proper maintenance. I regard a firm which maintains patchsets as a positive; this signals they are actually willing to devote resources to maintenance. They would not have written and shipped them had they not been willing to; most especially not at a firm like Microsoft which is well aware of the consequences.
While Sebastian didn't mention these, there are also a number of other drawbacks to selenium other than selenium sticking to open protocols. The most glaring of which is that most of the browser vendors do not support getting non-standard attribute values (such as the aria* family) which are highly relevant. You must resort to simply executing javascript code, which more or less defeats the purpose of 90% of the Selenium API. This is the approach pretty much all the polyfills in Selenium::Remote::Driver take.
Another huge controversy over the last half-decade was the "Element Overlap" check, which was buggy for years (especially when negative margin was involved) and still can't be turned off reliably. By contrast, Playwright's check is easy to turn off and has always worked correctly. It sounds like Microsoft learned the right lesson instead of being insensitive to the will of the vast majority of users.
The "Upgrade" to the WC3 protocol also removed a great deal of functionality, while giving us less new features than were removed from the JSONWire spec. Back then the drivers were even more unreliable than they are now; The primary point of the standards was to try and find a minimum set of functionality that they could reliably maintain, an effort which is a clear failure at this point.
Microsoft's approach of just letting the browser vendors do their thing and adapt to them rather than demanding they adapt to testers is far better. In my career this always works out the same way. Your life as a developer and tester gets a lot better when you take the software you work with largely as a given.
All the points above lead one to conclude the only thing you can rely on in selenium is the javascript interpreter. So why not just skip selenium and write tests with something like protractor? This is in fact what a number of organizations have done.
It's not like the WC3 API gives you anything above and beyond what the JS interpreter can give you, so it makes a lot of sense from a practical perspective. Playwright on the other hand gives you easy access to everything enabled by the DevToolsProtocol on every browser with a unified API. Selenium 4.0 offers the ability to talk to the DevToolsProtocol, but without a unified API. This is why I consider Selenium an obsolete protocol which has been leapfrogged entirely by Playwright.
This is not to say that Selenium does not have some features which are still not met by the Playwright team. In particular the built-in Selenium Grid which has been massively strengthened in Selenium 4.0. This is enabled by it being a server based approach, rather than just a library for talking to the browser.
Obviously, this is quickly solved with but another layer of abstraction. I did precisely that to accomplish the first Playwright client not made by Microsoft. The server-based approach I took would allow me to replicate Selenium's grid functionality in the future with Playwright... but that's probably not needed in our modern era of coverage reporters and containers. That's why my current project Pairwise is aimed at simplifying this workflow specifically.
Back in the JSONWire days, Microsoft UI had the genius idea to unify desktop testing under the Selenium API with WinAppDriver. This unfortunately has been abandoned in favor of making VSCode a world-beater. This was clearly the right move for microsoft, as even I have been largely converted from my vim + tmux workflow. I still think this is an amazing idea, and (if nobody beats me to it) I want to make an equivalent for linux (using XTest) and OSX...and windows, but all using the Playwright API instead.
Playwright also made another design decision which guarantees it will be easy to spread and write clients for. It ships with a machine-readable specification, while Selenium has never (and likely will never do so). Since SeleniumHQ's 4.0 JAR made breaking changes, I decided to make a new client Selenium::Client. I liked the approach of dynamically making classes based upon a spec, and did so for the next generation selenium client. However, this required that I parse the specification document, which was a nontrivial task (see Selenium::Specification).
The intention long-term is to replace the guts of Selenium::Remote::Driver with Selenium::Client to reduce maintenance burden; this will take some time given how difficult it will be to untangle due to the module being a big ball of mud.
The rest of Sebastian's article goes over the practical points of embedding your perl application inside Node to test it. Much of these are the same concerns (ensuring the server is up before testing, bringing it down correctly, ensuring deps) which I had with the server. Similarly, build toolchain issues are about the same either way; you'll have to wrangle both cpan and npm one way or another. In the end it comes down to personal preference; do you want to write Playwright in perl or JS?
For guys like Sebastian and I who are as fluent in Javascript as Perl, his approach actually makes a lot of sense and is a lot less work than making a module like Playwright-perl. The path to scaling is also less work than building in a grid-like functionality to Playwright-perl; Kubernetes deployment of a bunch of containers each running some subset of tests and using a coverage reporter isn't exactly rocket science. That said, doing the same with scripts built atop playwright-perl won't exactly be difficult either.
For those of you more comfortable in Perl than JS, I think you'll be well served by playwright-perl. Feel free to give it a shot if this sounds like you. If you like it a lot, feel free to send me a gratuity, become a patron, or log some bugs if you don't like it so much.
I've been writing a bunch of TypeScript lately, and figured out why most of the "Async" modules out there are actually fakin' the funk with coroutines.
Turns out even pedants like programmers aren't immune to meaning drift! I guess I'm an old man now lol.
Article mentioned: Troglodyne Q3 Open Source goals
